docs.roboticcrowd.com
サイト上の情報を CSV に抽出
概要
AUTORO Assistantを使って、ウェブサイトの取得したいデータを抽出してCSVに作成する方法を説明します。
事前に、Chrome に AUTORO Assistant という拡張機能をインストールしている必要があります。 インストール方法は、こちら をご覧ください。
では、始めましょう。
このチュートリアルのゴール
今回は、オートロ株式会社のブログの「日付」「タイトル」「ブログ分類名」の3つのデータを抽出し、CSVにダウンロードします。
手順
- レコーディングを開始するサイトを開く
- AUTORO Assistant のポップアップを表示して、EXTRACT DATAボタンでデータ抽出を開始する
- 抽出操作を開始する
- STOPボタンでデータ抽出を停止する
- データをCSVにダウンロードする
1. レコーディングを開始するサイトを開く
はじめに、オートロ株式会社のブログページ(https://autoro.io/blog/) を開いてください。
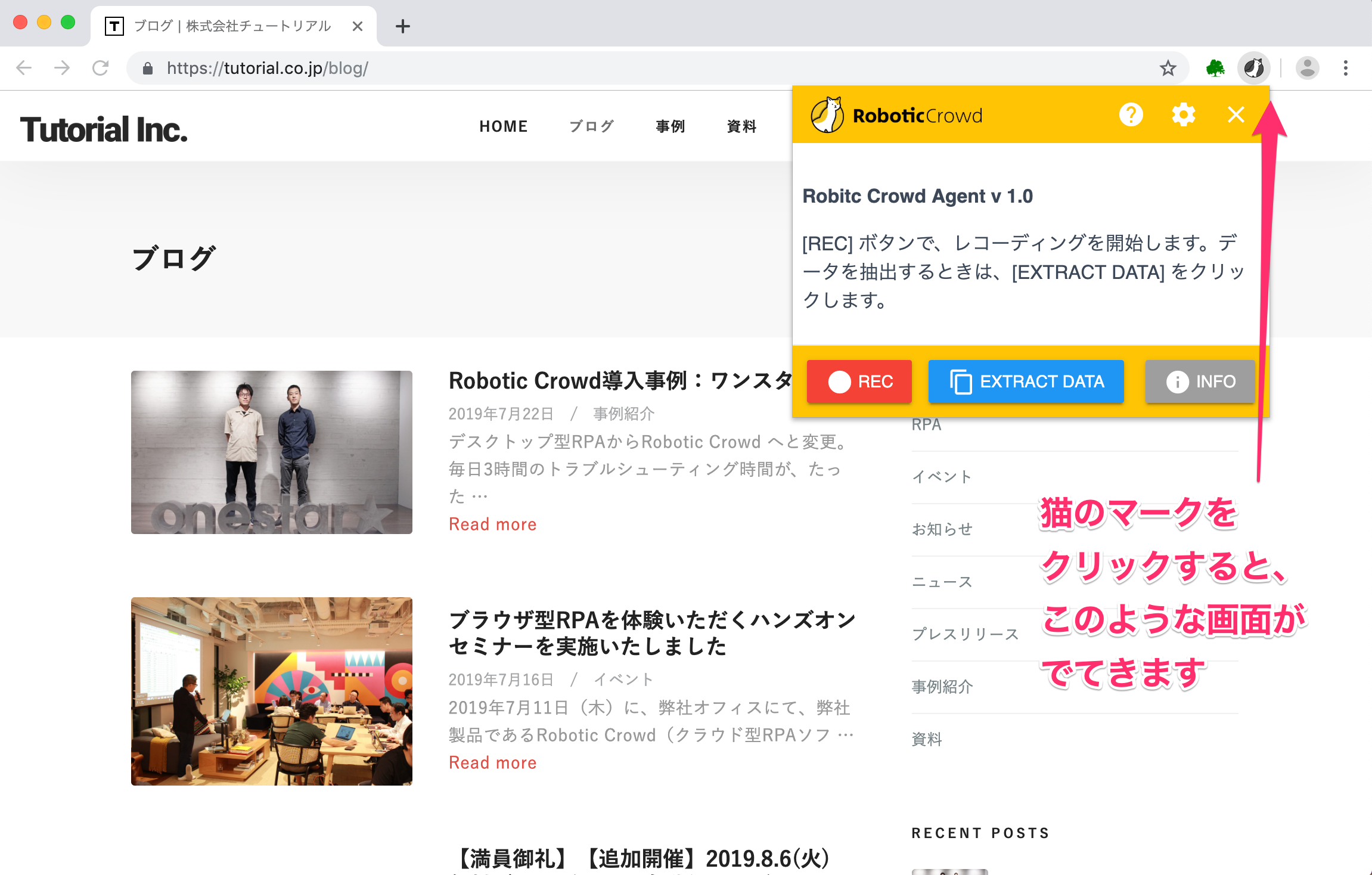
Chrome のアドレスバー右側にある、肉球のマークをクリックしてください。 すると、下図のように、ポップアップが表示されます。
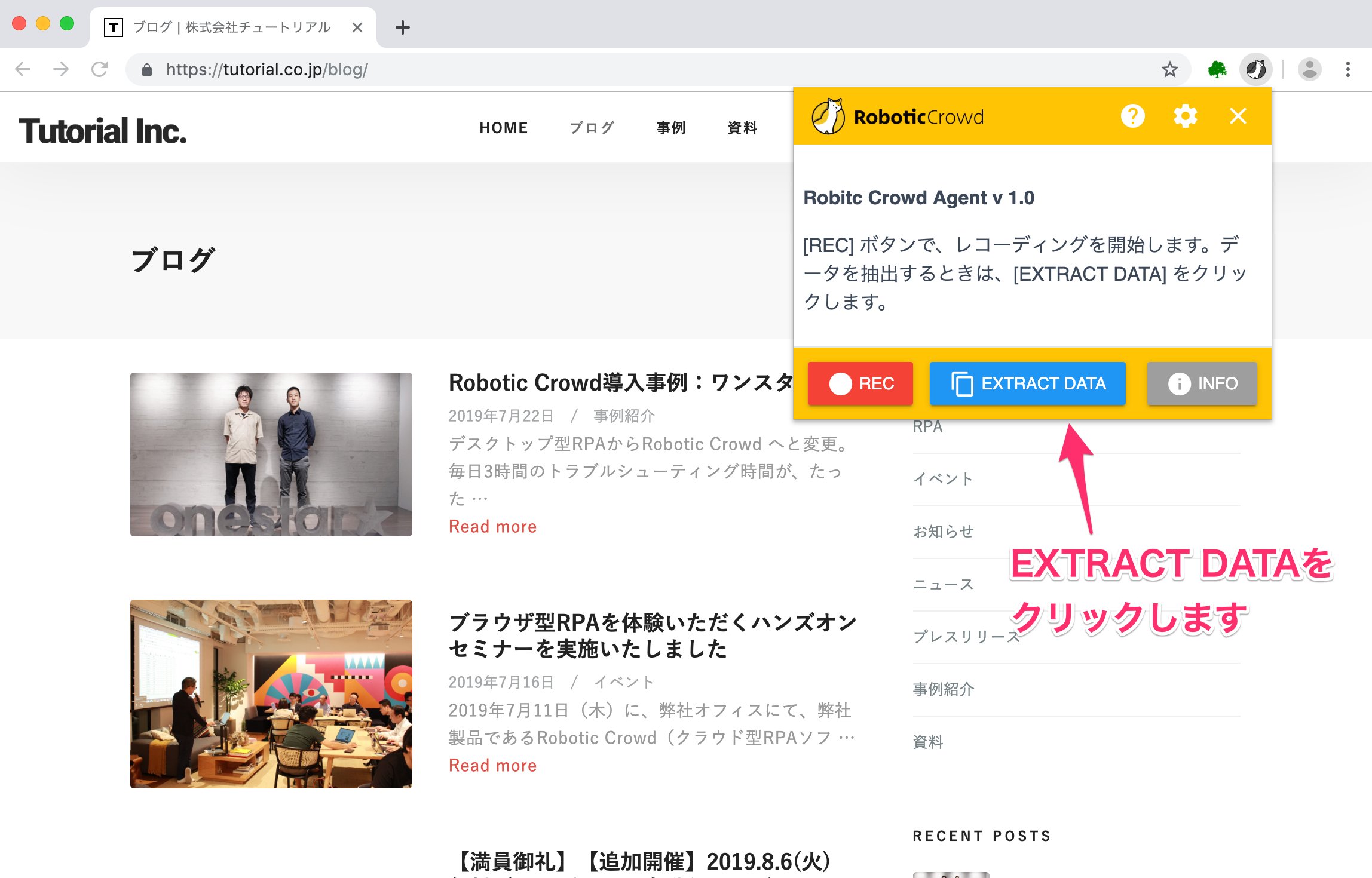
2. AUTORO Assistant のポップアップを表示して、EXTRACT DATAボタンでデータの抽出を開始する
前回は「REC」を使用しましたが、今回は「EXTRACT DATA」を使用します。 「EXTRACT DATA」をクリックしてください。
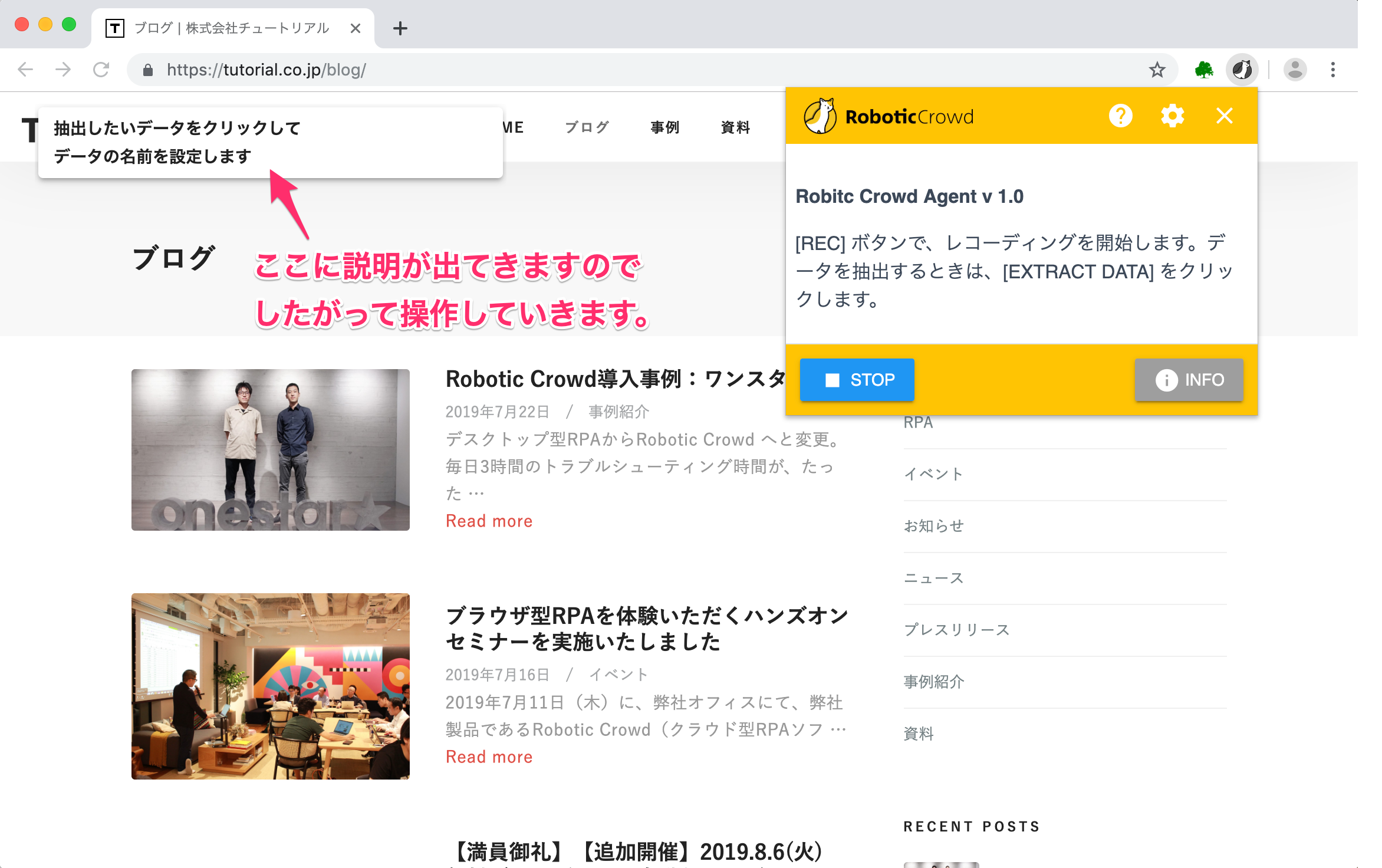
「EXTRACT DATA」をクリックすると下図のように、 ページ左上に使い方の説明が表示されますので、その説明にしたがって操作していきましょう。
3. 抽出操作を開始する
はじめに、ブログの日付を抽出します。 更新日時の部分にカーソルを合わせて、クリックしてください。
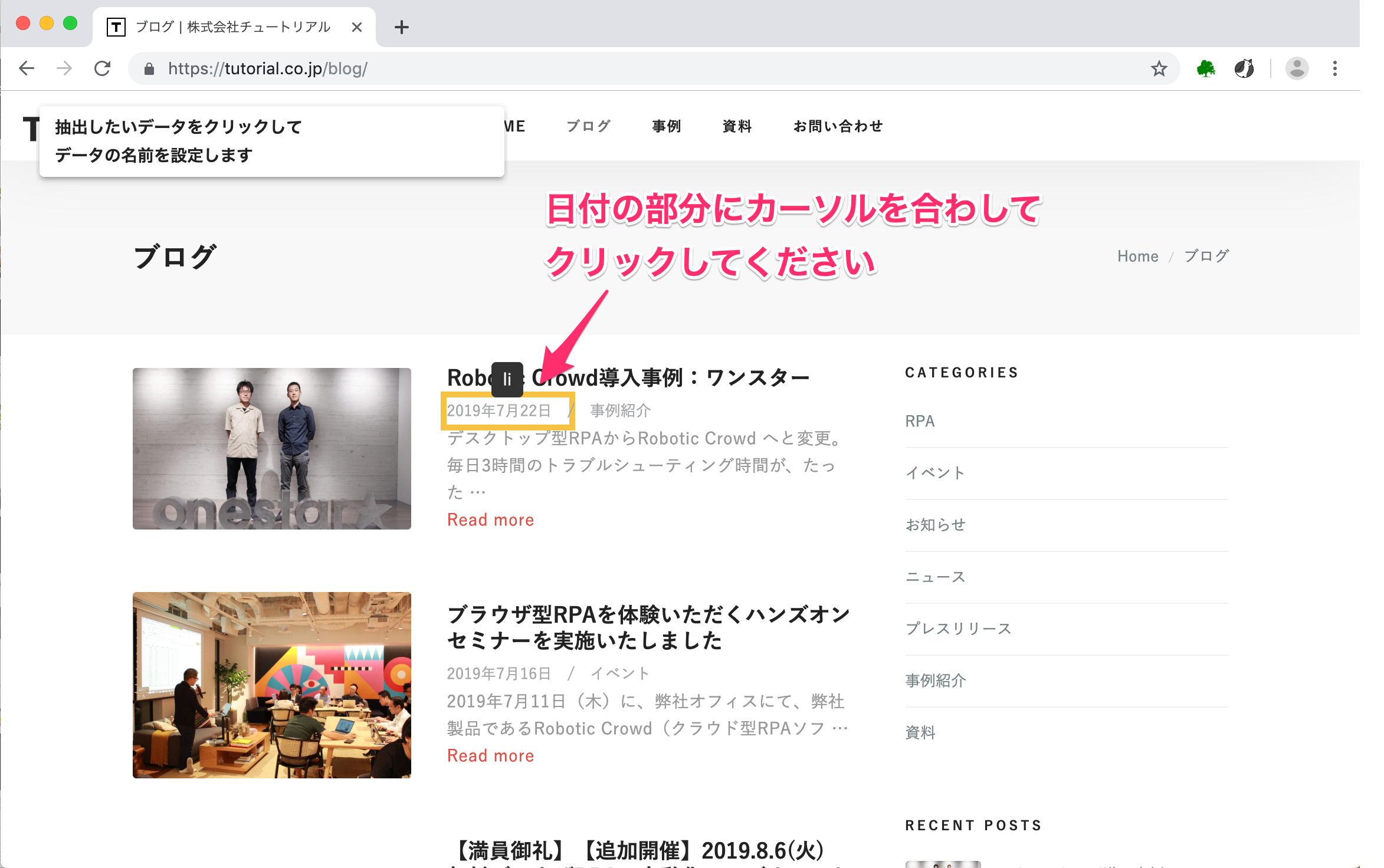
更新日時の部分をクリックすると、下図が表示されます。 Data Nameの部分に「日付」と入力し、次へを押してください。
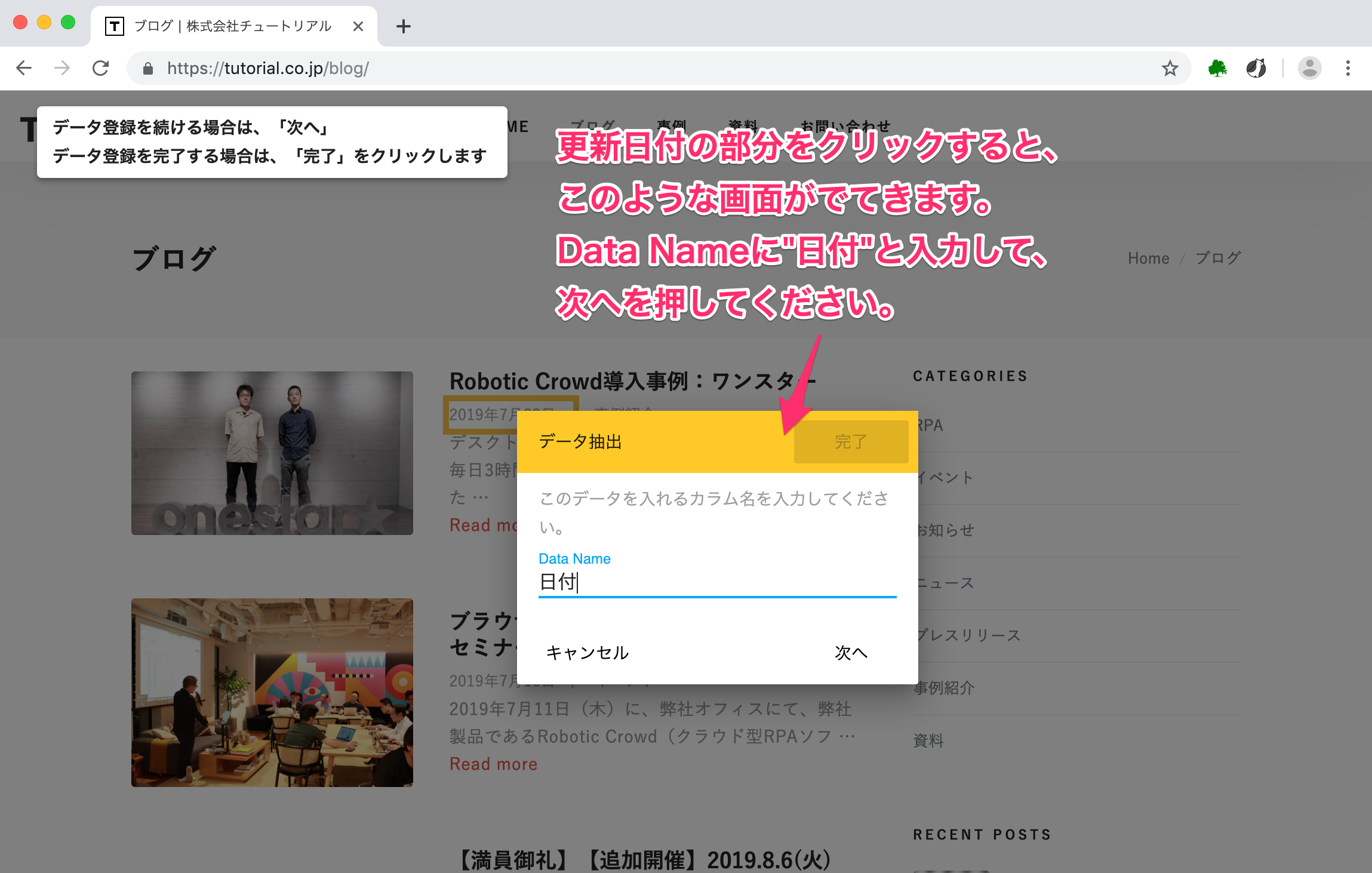
最新記事の更新日時の部分が青く囲まれたことが分かります。 連続したデータを抽出したいので、「次にどこのデータを連続して抽出すれば良いのか」をロボットに示す必要があります。 そのため、2つ目のブログの更新日時をクリックしてください。
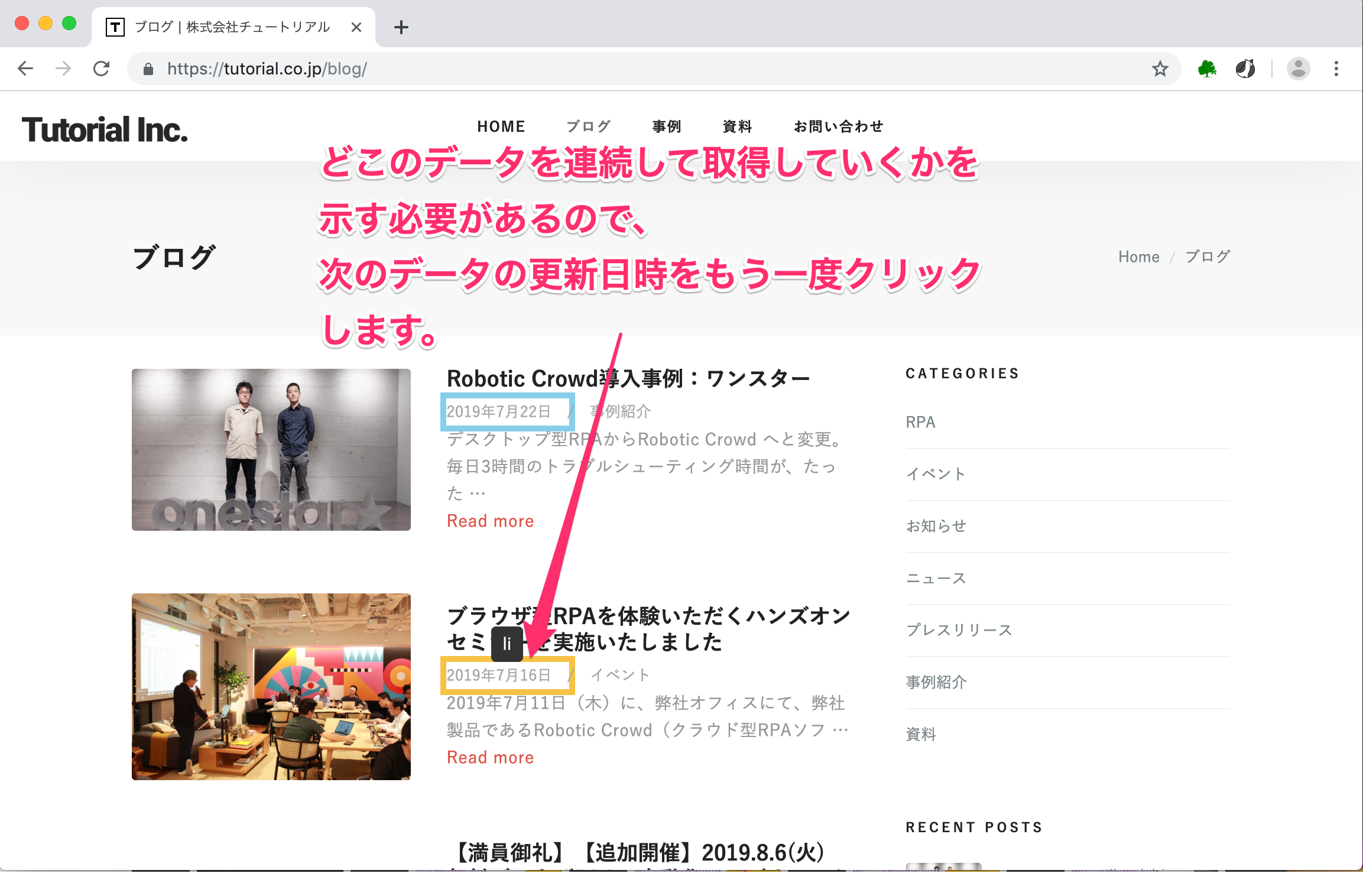
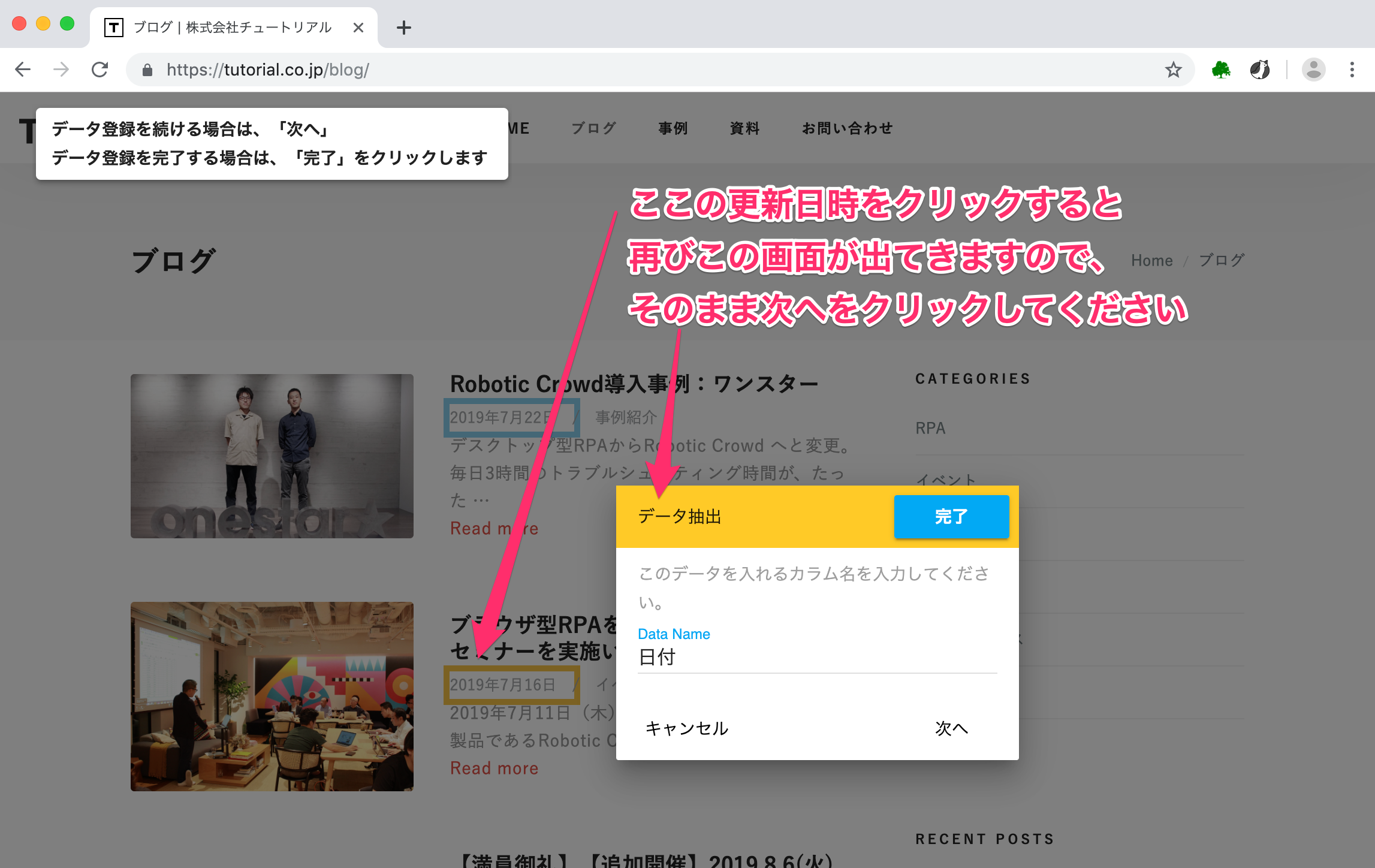
クリックすると、再び下図のものが表示されます。 Data Nameの部分に、すでに日付というものが入力されています。そのまま次へを押してください。
「次にどこのデータを連続して抽出すれば良いのか」をロボットに示すために日付を2回抽出しましたが、サイトによっては1回抽出すれば全て青く囲まれる場合もあります。 その場合は、2回抽出する必要はありません。
このページ全てのブログの更新日時の部分が、青く囲まれました。
*今回は「次にどこのデータを連続して抽出すれば良いのか」をロボットに示すために日付を2回抽出しましたが、サイトによっては1回抽出すれば全て青く囲まれる場合もあります。その場合は、2回抽出する必要はありません。
次に、ブログタイトルを抽出します。抽出方法はこれまでと同様です。ブログタイトルの部分にカーソルを合わせてクリックしてください。
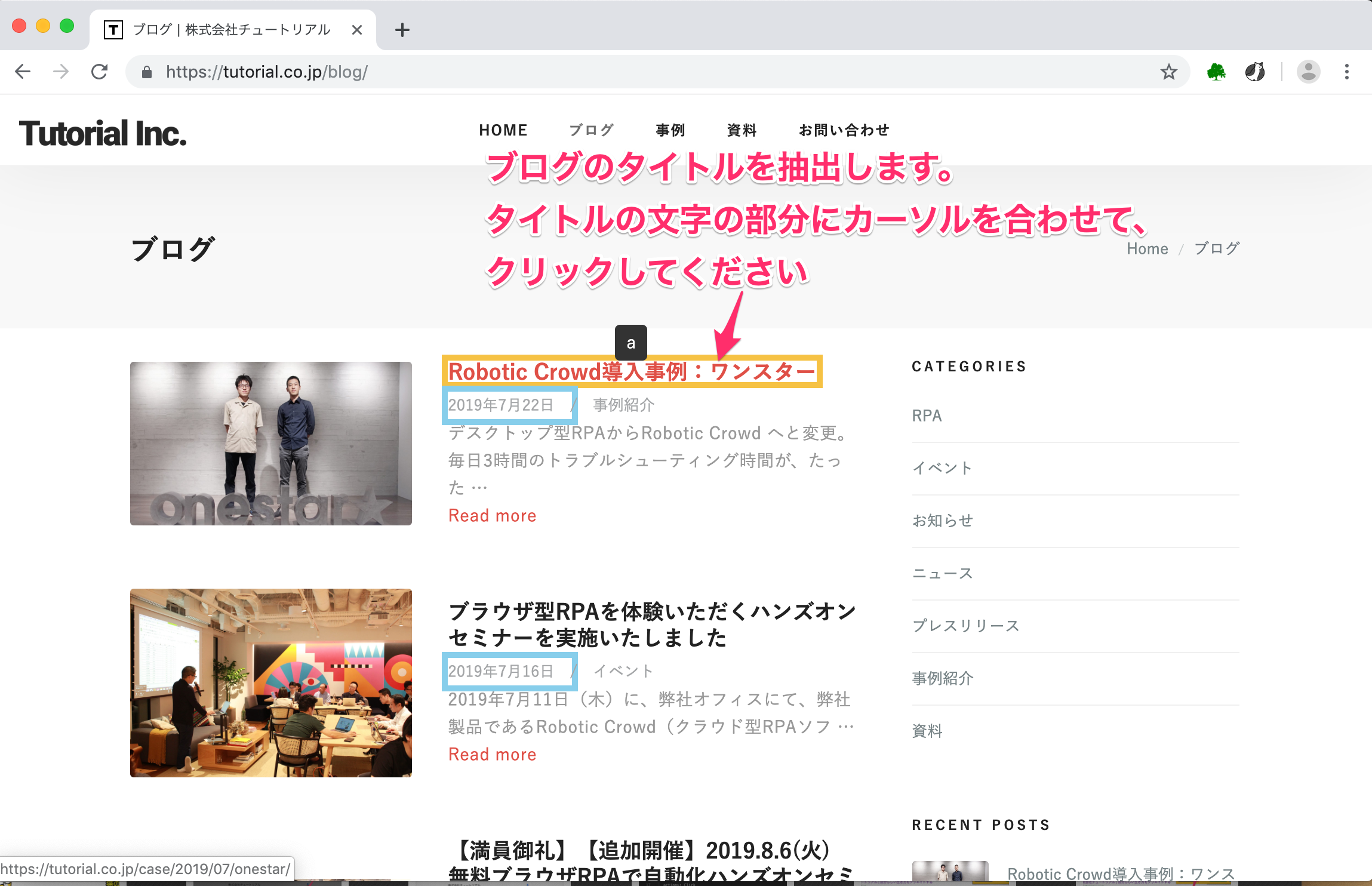
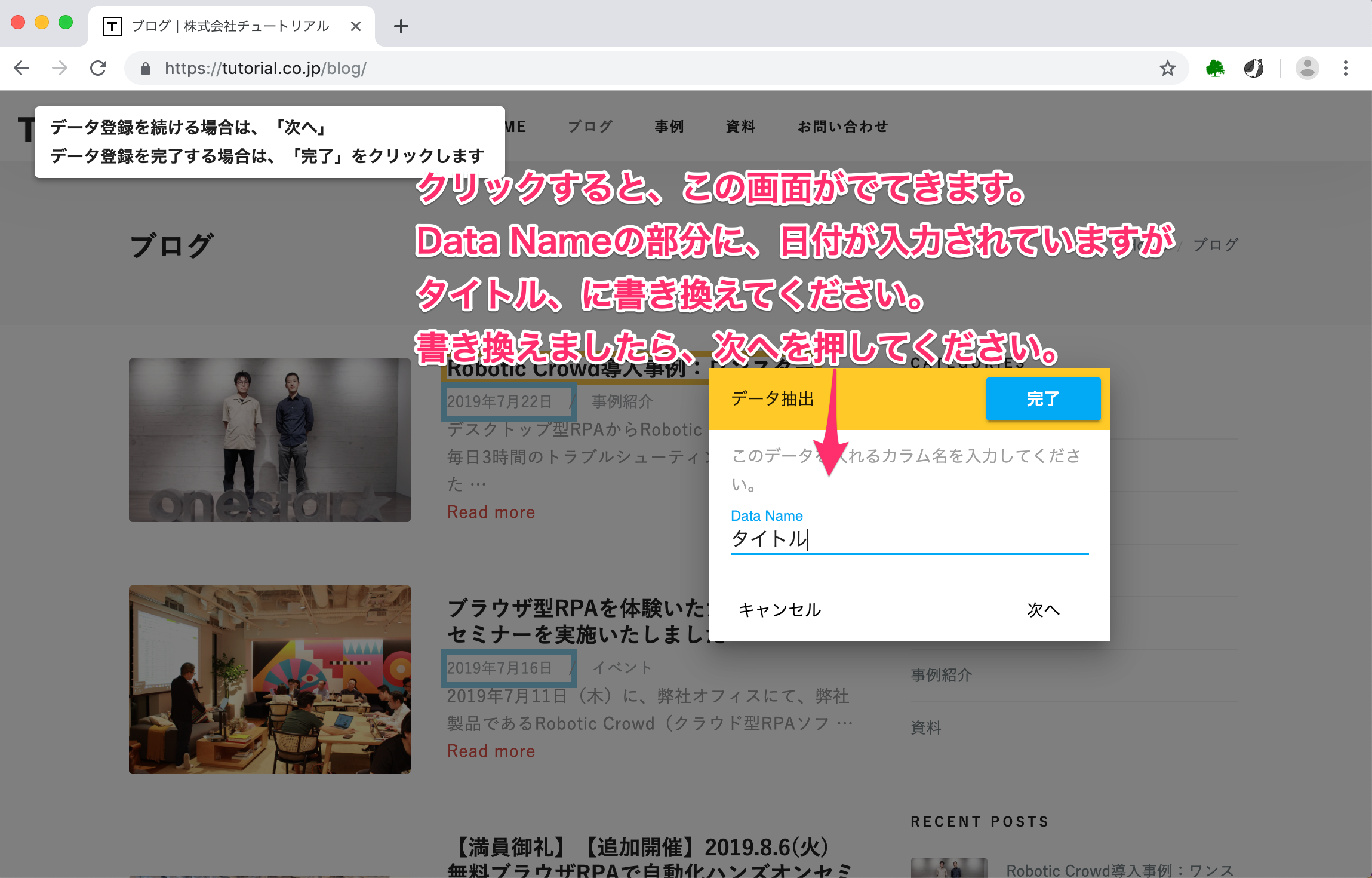
ブログタイトルの部分をクリックすると、Data Nameを入力する画面が表示されます。 Data Nameの部分にすでに「日付」と入力されていますが、 今回抽出したいデータはタイトルなので、DataNameを「タイトル」に書き換えてください。 書き換えましたら、次へを押してください。
最後に、ブログ分類名を抽出します。抽出方法はこれまでと同様です。
ブログ分類名の部分にカーソルを合わせてクリックしてください。
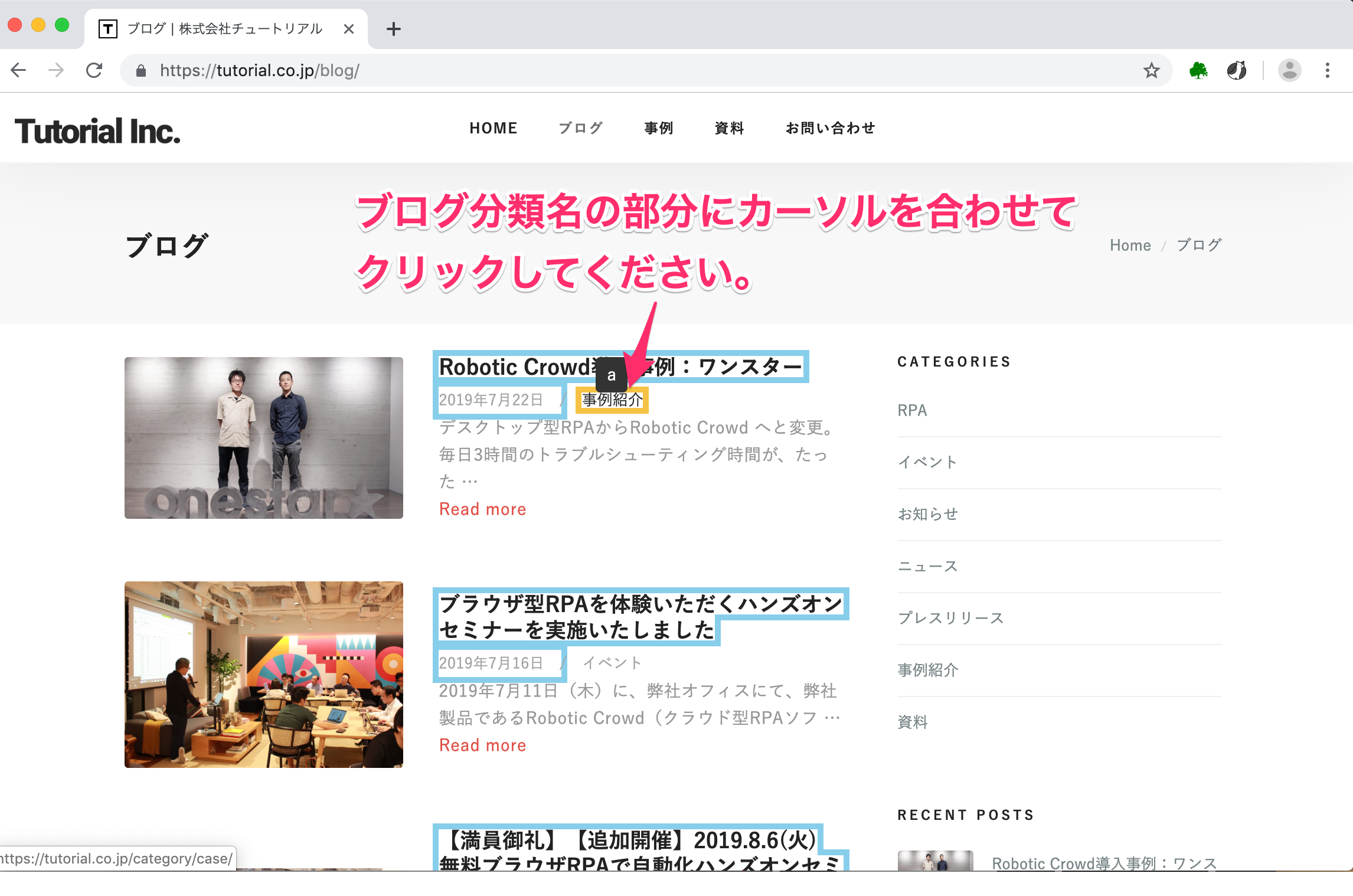
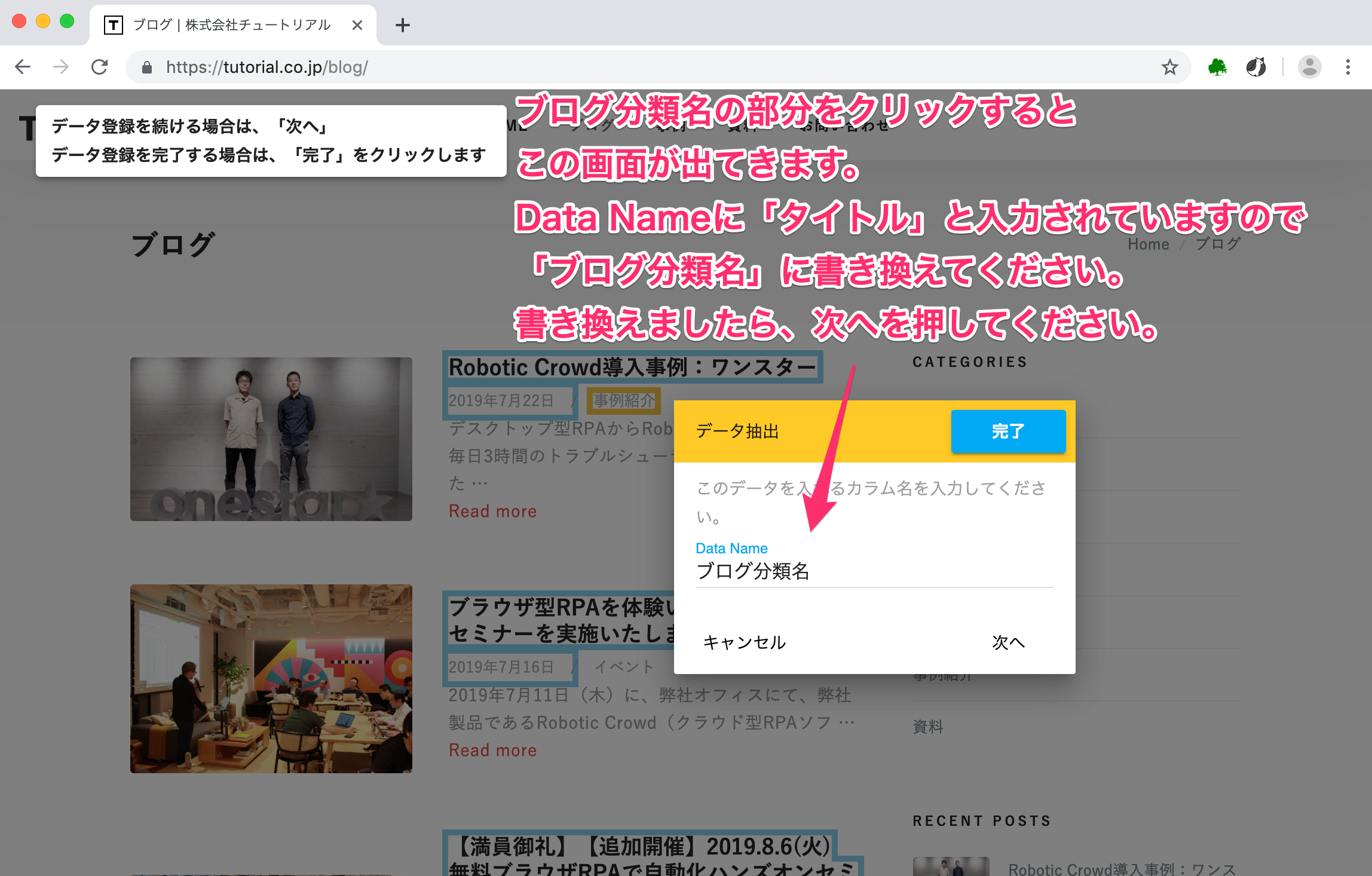
クリックするとData Nameの画面が出てきます。
Deta Nameの部分にすでに「タイトル」が入力されていますが、今回抽出したいデータはブログ分類名なので、Data Nameを「ブログ分類名」に書き換えてください。書き換えましたら、次へを押してください。
次へを押すと、このページにある全ブログの「日付」「タイトル」「ブログ分類名」が青く囲まれていることがわかります。 現在の画面は以下のようになっています。
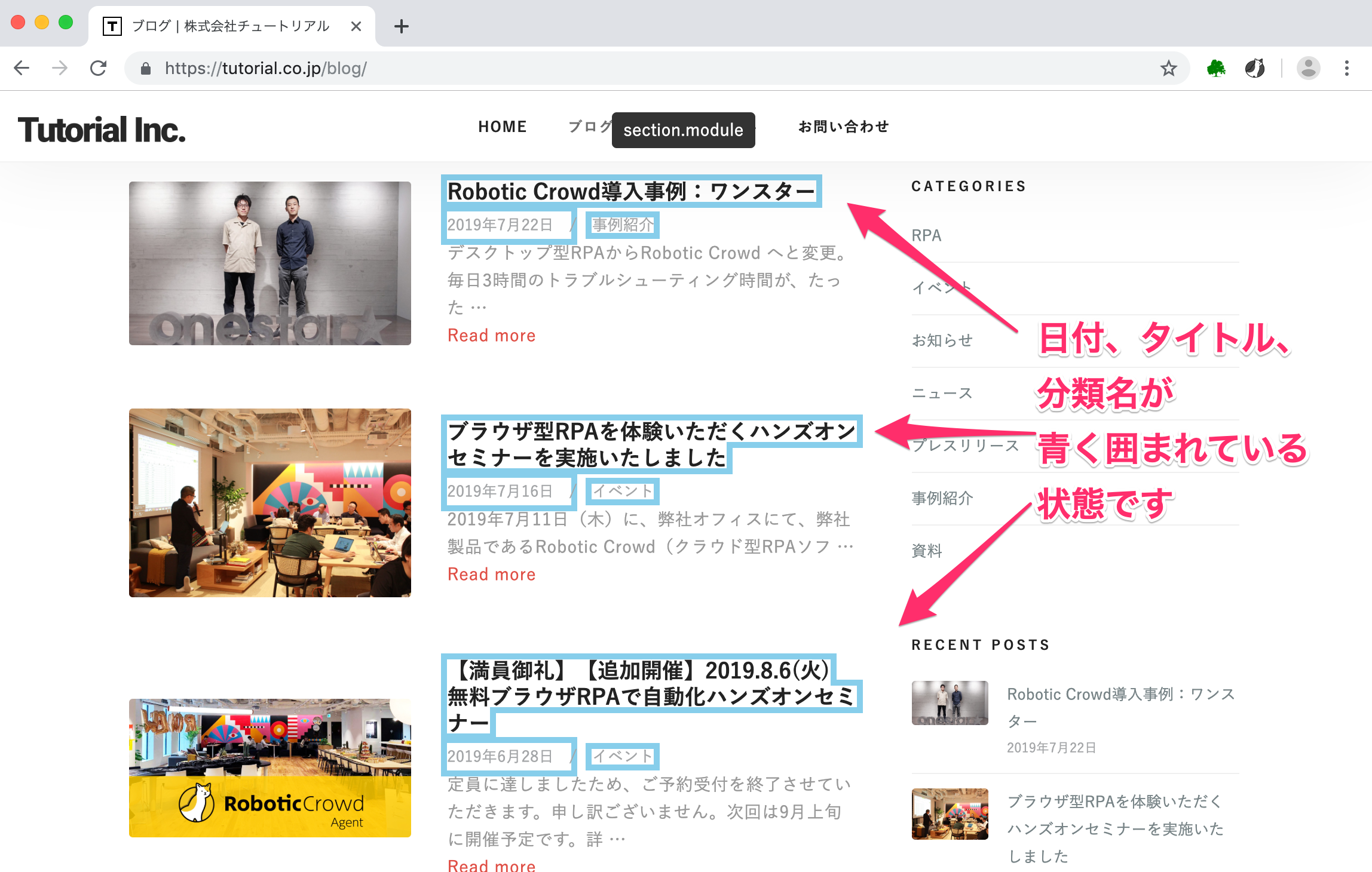
4. STOPボタンでデータの抽出を停止する
データは全て抽出できました。 データの抽出を停止します。肉球のマークをクリックして「STOP」ボタンを押してください。
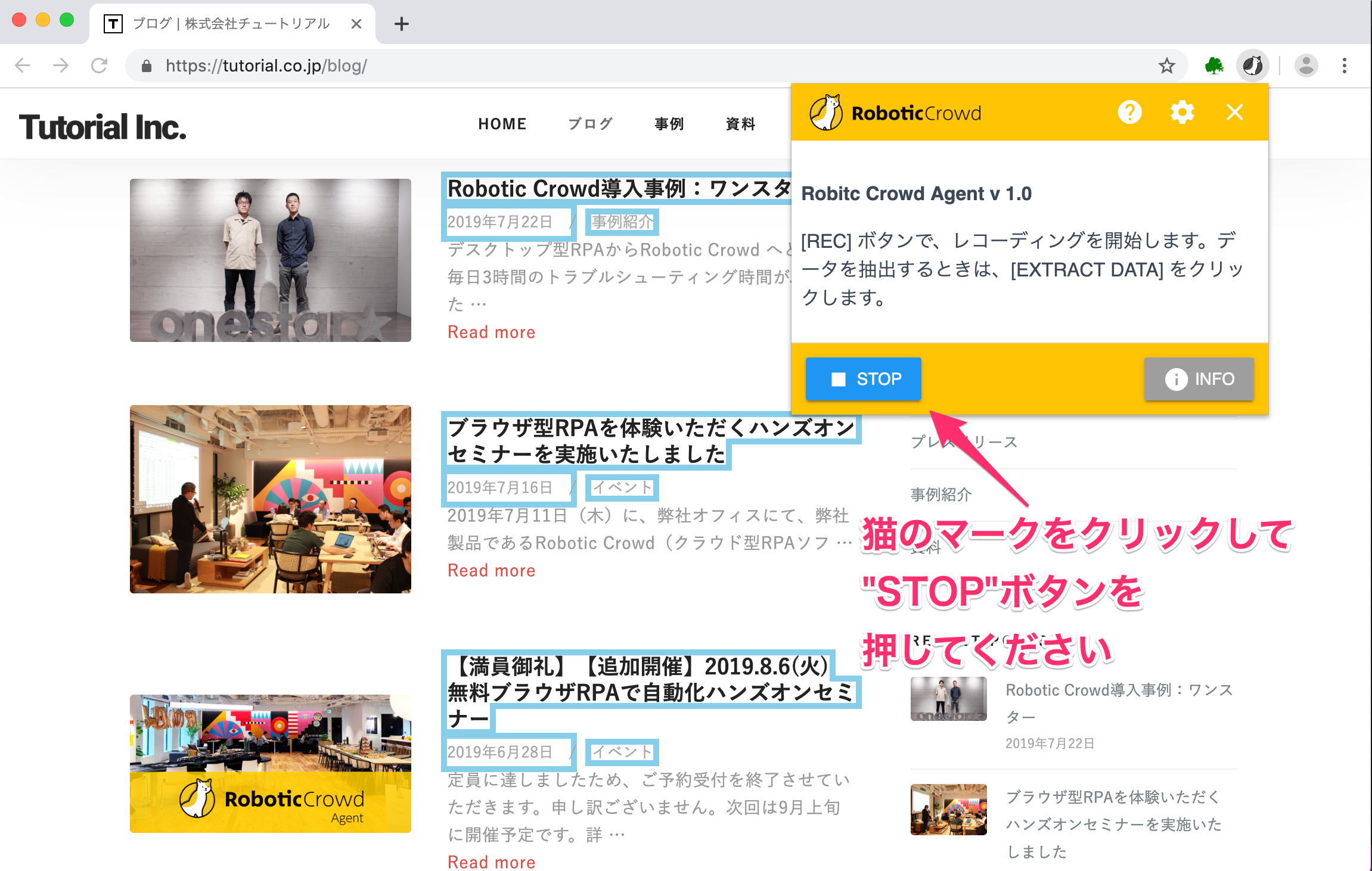
「STOP」を押すと、操作が記録されていることがわかります。
「COPY」を押してテキストエディタ等に貼り付けて全体のワークフローを確認してみてください。 (「AUTORO Assistantで既存のワークフローを実行する」という記事で使用しますので、テキストエディタ等に保存しておくと便利です。)
それでは「TRY」をクリックして、確認してみましょう。
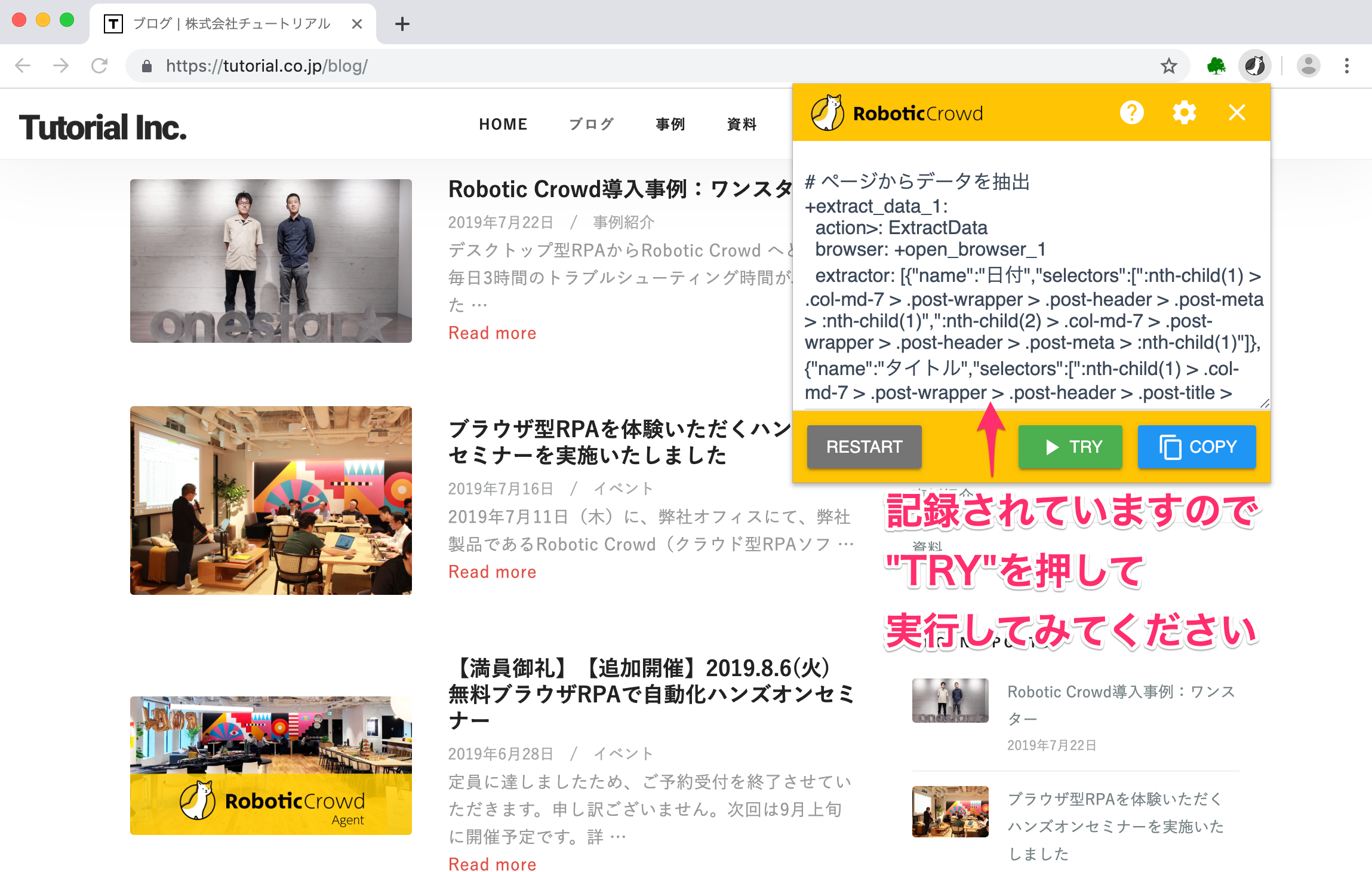
5. データをCSVにダウンロードする
「TRY」を押すと、データを抽出できていることがわかります。
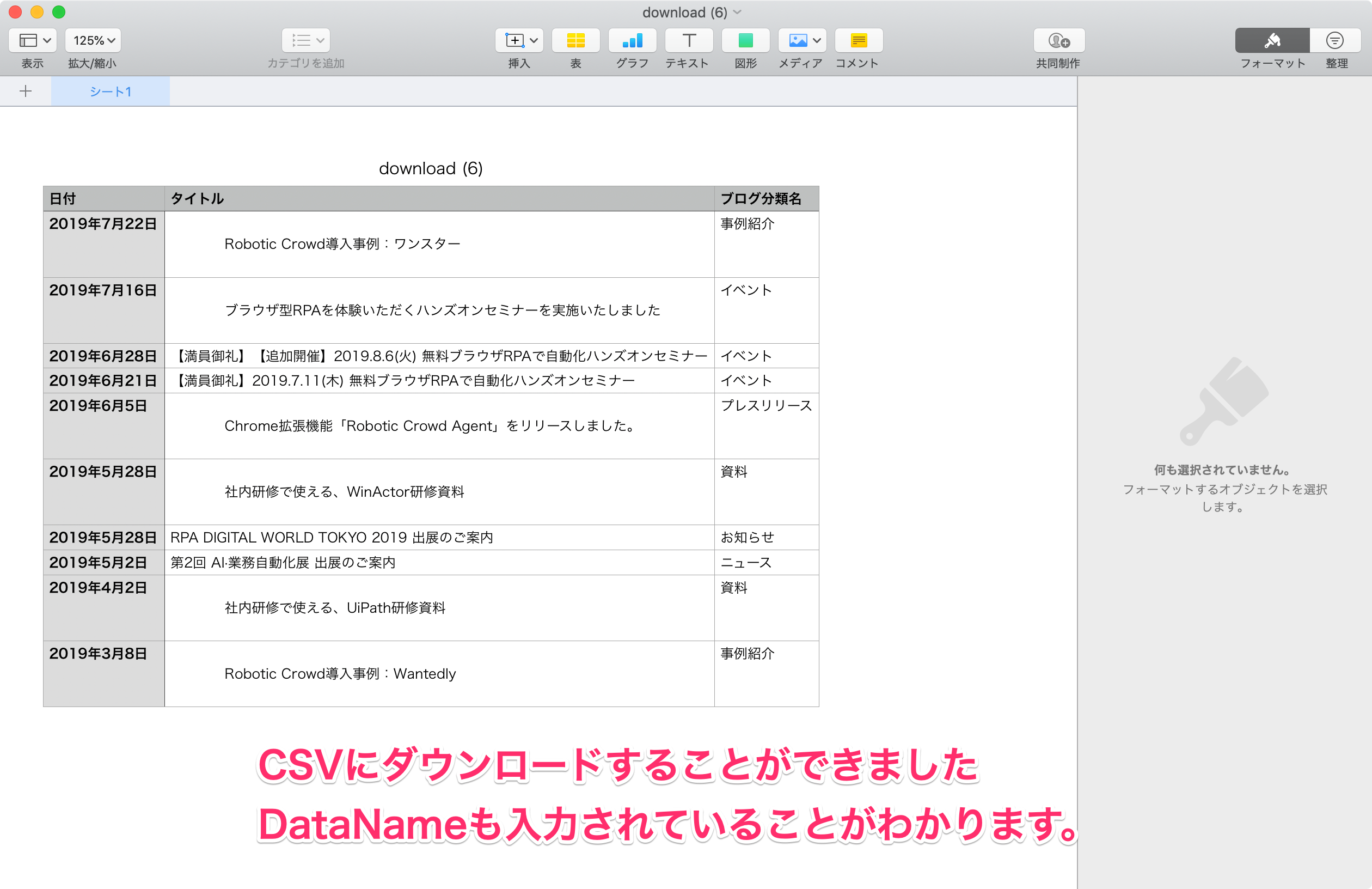
最後に、抽出したデータをCSVにダウンロードしましょう。右下にある「ダウンロードCSV」をクリックしてください。
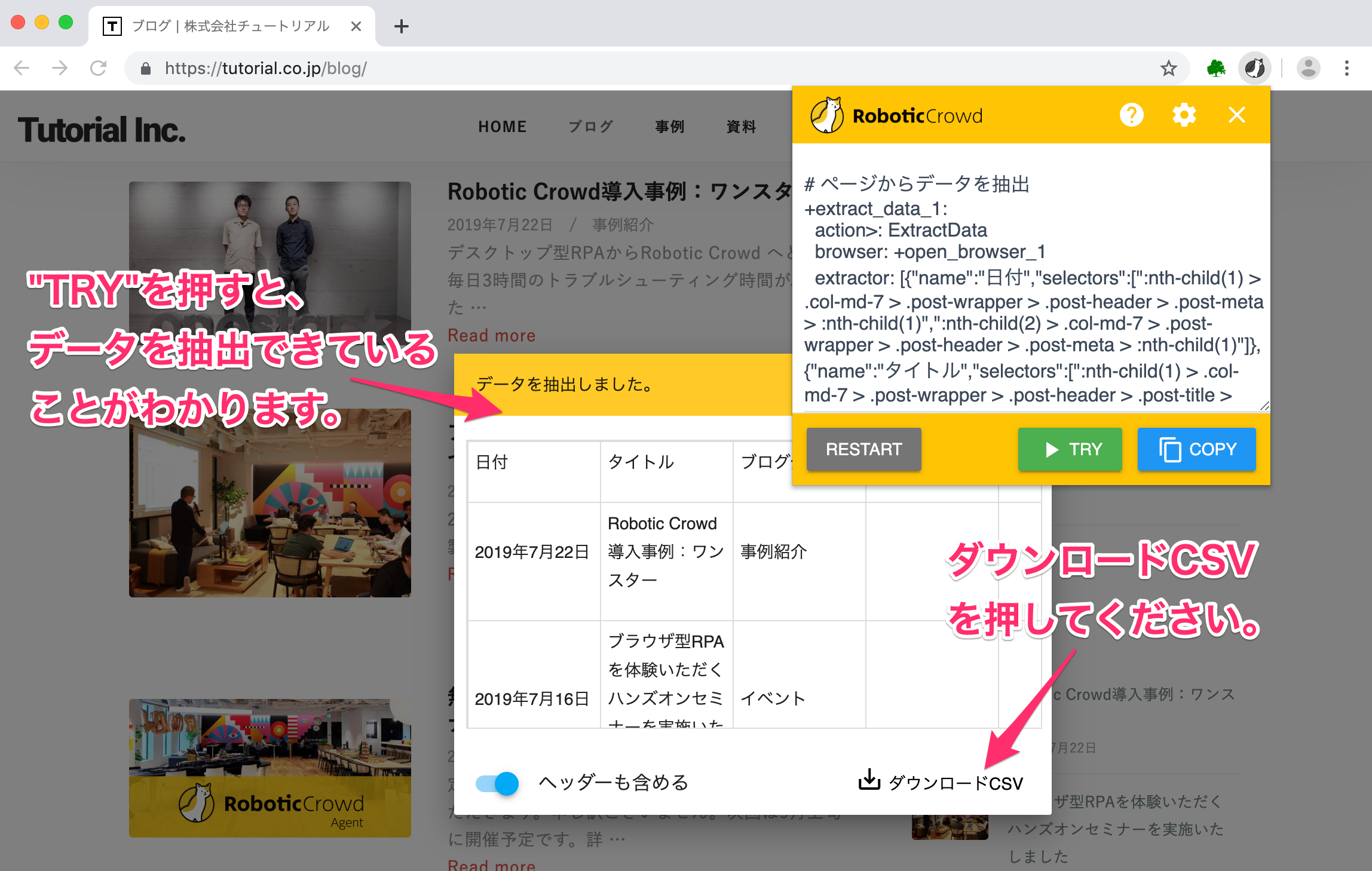
ダウンロードCSVをクリックすると、先ほどの抽出されたデータがCSVにダウンロードされたことがわかります。設定したDataNameの「日付」「タイトル」「ブログ分類名」もヘッダーに入力されています。
お疲れ様でした。
今回記録されたワークフローは「AUTORO Assistantで既存のワークフローを実行する」という記事の際に使用しますので、テキストエディタ等に保存しておくと便利です。
ウェブサイトのデータをCSVに抽出する方法について説明しました。複数のデータをまとめてCSVに抽出できることがわかったと思います。
今回説明したような、ページからのコピペを繰り返すなど似たような作業を繰り返すのは、面倒ですよね。
次は、繰り返し作業の記録方法についてご紹介します。